Reading cities
like a
pedestrian
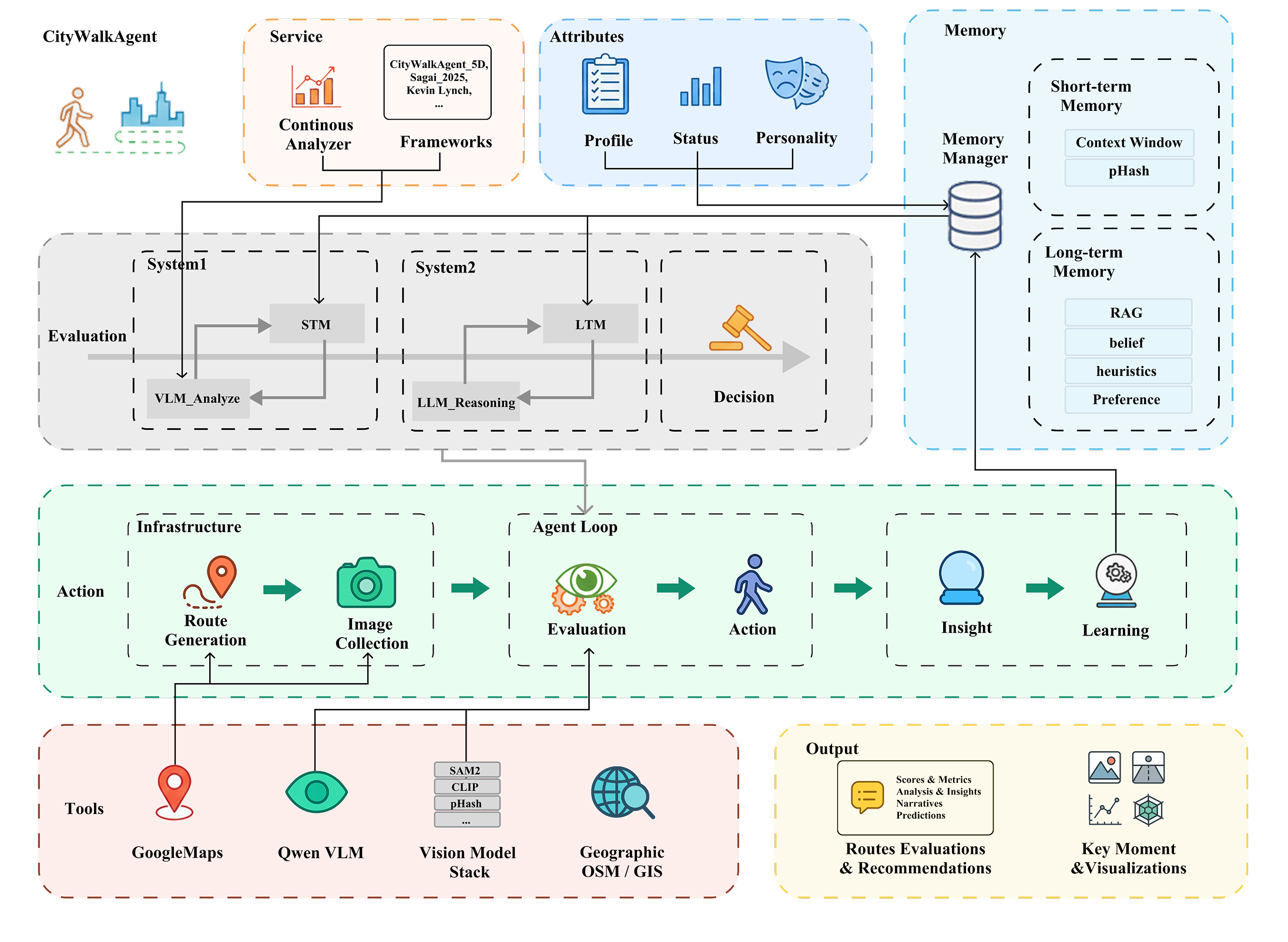
CityWalkAgent is an autonomous urban walking agent that navigates and evaluates pedestrian environments through Vision-Language Models, treating walks as continuous narratives rather than aggregated point assessments.
0.85
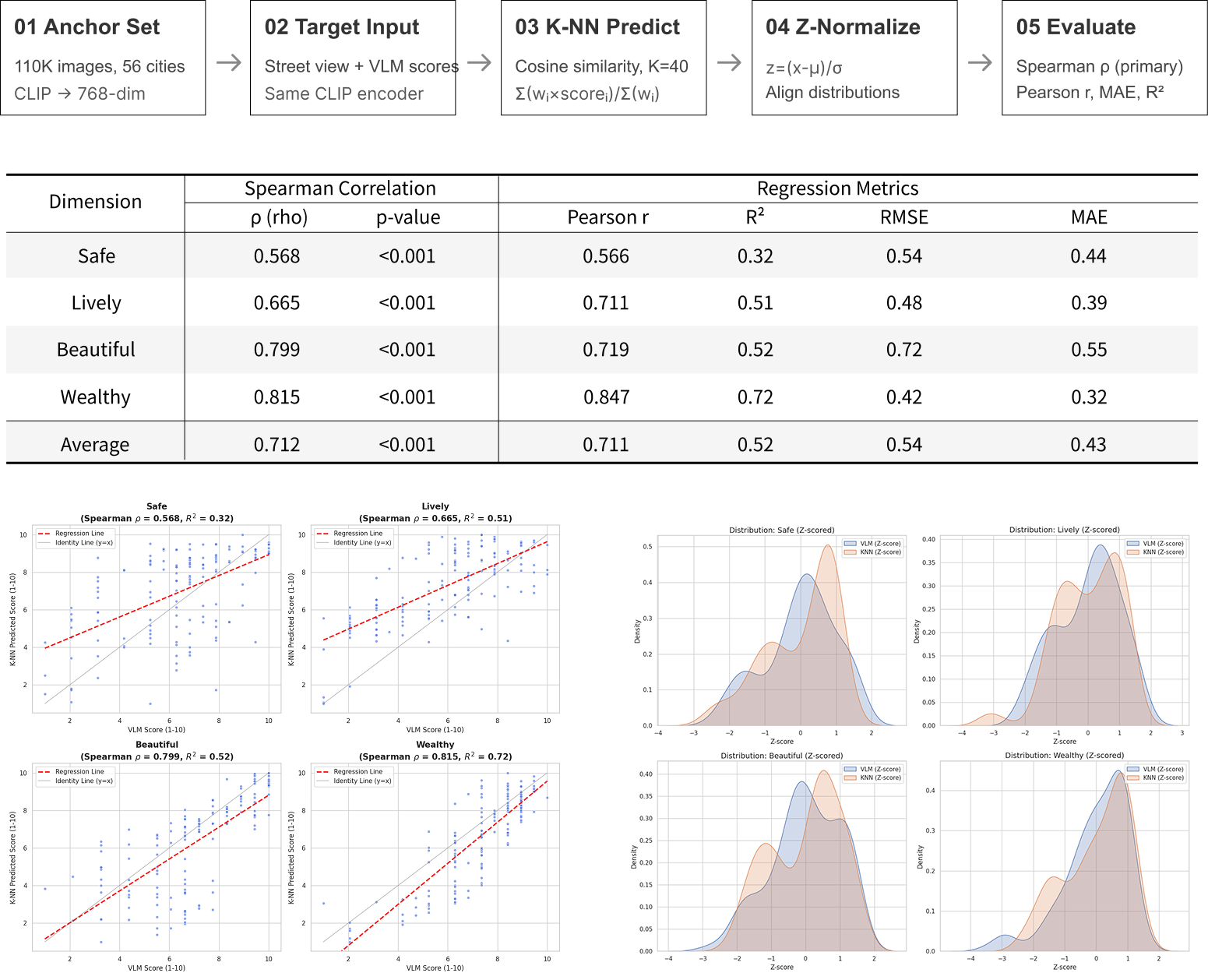
Spearman ρ vs. human
1.1M+
Place Pulse Data validated
5+
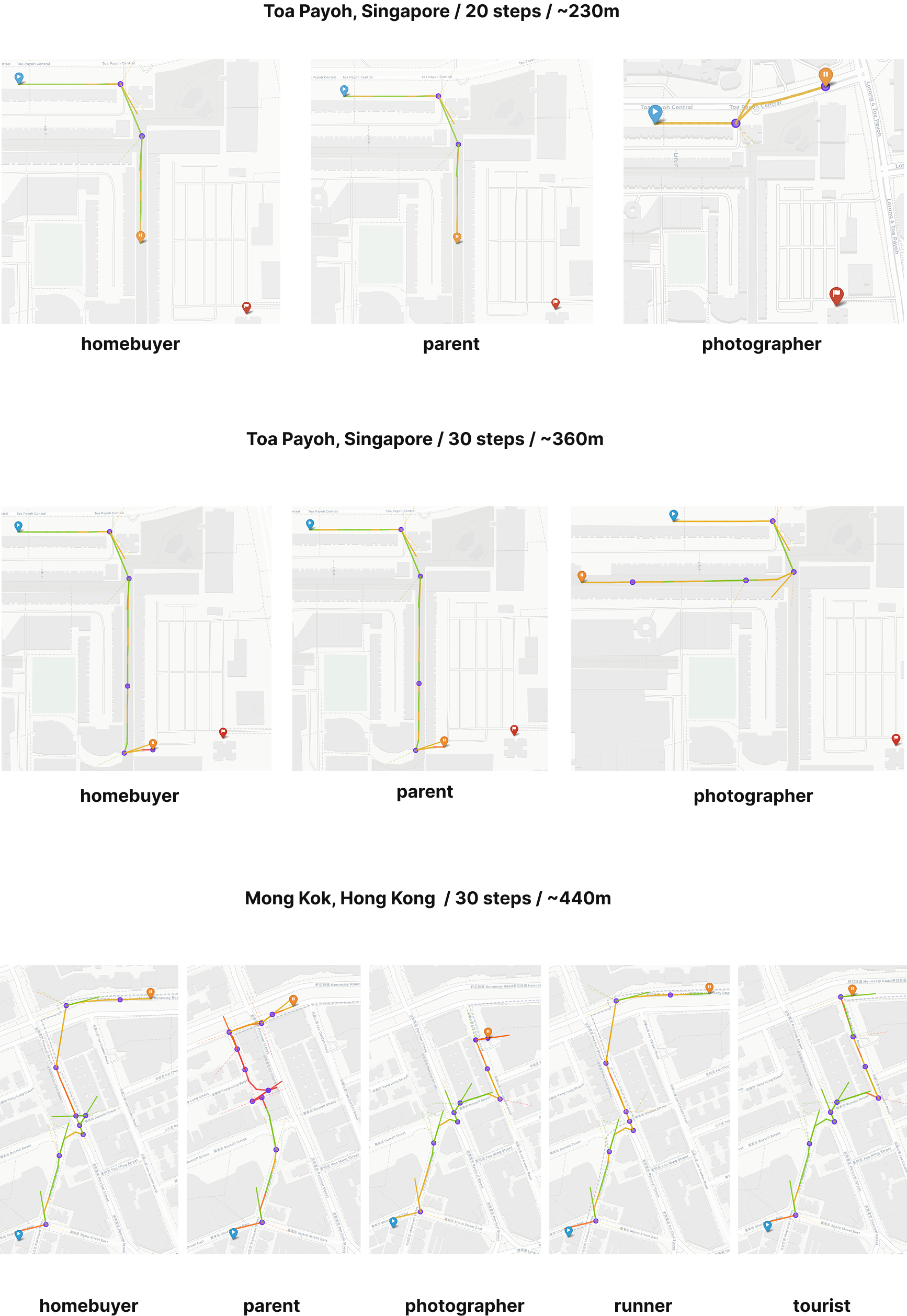
Agent personas implemented
~12s
Per-intersection inference